⏳ Time Series
Evolve multi-stage ML pipelines tailored for sequential data, predicting future temporal patterns.
Note
Time series evolution handles look-ahead bias, temporal walk-forward splits, and sequence alignment automatically.
What It Does
The time_series family genetically evolves pipelines for forecasting or temporal classification:
Differencing → LagFeatures → RollingStats → TimeModel₁ → TimeModel₂ → Fusion
Each candidate is evaluated on how well it predicts future patterns using chronological splits to prevent data leakage.
Quick Start
import numpy as np
import pandas as pd
from veox import VeoxEvolver
# Generate basic sequence
t = np.arange(300)
base_signal = 0.02 * t + 3.0 * np.sin(2 * np.pi * t / 50) + np.random.normal(0, 1.0, 300)
df = pd.DataFrame({"f0": base_signal})
# Target is next-step direction
df["target"] = (np.diff(base_signal, append=base_signal[-1]) > 0).astype(int)
evolver = VeoxEvolver("time_series")
evolver.fit(data=df, target_column="target", max_generations=3)
print(f"Best Forecast Skill: {evolver.best_fitness_:.4f}")
Full Example
import os
import numpy as np
import pandas as pd
from veox import VeoxEvolver
api_url = os.environ.get("VEOX_API_URL", "http://127.0.0.1:8090")
# 1. Generate a synthetic time series dataset
rng = np.random.RandomState(42)
n_samples = 300
t = np.arange(n_samples, dtype=float)
# Features: lagged values, rolling stats, synthetic indicators
trend = 0.02 * t
seasonal = 3.0 * np.sin(2 * np.pi * t / 50)
noise = rng.normal(0, 1.0, n_samples)
base_signal = trend + seasonal + noise
df = pd.DataFrame({
"f0": base_signal,
"f1": np.roll(base_signal, 1), # lag-1
"f2": np.roll(base_signal, 5), # lag-5
"f3": pd.Series(base_signal).rolling(5, min_periods=1).mean().values,
"f4": pd.Series(base_signal).rolling(10, min_periods=1).std().fillna(0).values,
"f5": rng.normal(0, 0.5, n_samples), # noise feature
"f6": seasonal + rng.normal(0, 0.3, n_samples),
"f7": np.clip(np.gradient(base_signal), -5, 5),
})
# Target: next-step direction (binary for simplicity)
future_return = np.diff(base_signal, append=base_signal[-1])
df["target"] = (future_return > 0).astype(int)
# Drop first few rows with NaN artifacts from rolling/lag
df = df.iloc[10:].reset_index(drop=True)
print(f"Dataset: {df.shape[0]} rows × {df.shape[1]} cols")
print(f"Target balance: {df['target'].mean():.1%} positive\n")
# 2. Connect & verify
evolver = VeoxEvolver("time_series", api_url=api_url)
evolver.health_check()
# 3. Evolve
evolver.fit(
data=df,
target_column="target",
max_generations=3,
population_size=15,
timeout_per_eval=30,
max_poll_time=120,
)
# 4. Results
print(f"Best Score: {evolver.best_fitness_:.4f}")
print(f"Best Pipeline: {evolver.best_pipeline_}")
print(f"Evaluations: {evolver.result_.total_evals}")
import os
import numpy as np
import pandas as pd
from veox import VeoxEvolver
api_url = os.environ.get("VEOX_API_URL", "http://127.0.0.1:8090")
# 1. Generate a synthetic time series dataset
rng = np.random.RandomState(42)
n_samples = 300
t = np.arange(n_samples, dtype=float)
# Features: lagged values, rolling stats, synthetic indicators
trend = 0.02 * t
seasonal = 3.0 * np.sin(2 * np.pi * t / 50)
noise = rng.normal(0, 1.0, n_samples)
base_signal = trend + seasonal + noise
df = pd.DataFrame({
"f0": base_signal,
"f1": np.roll(base_signal, 1), # lag-1
"f2": np.roll(base_signal, 5), # lag-5
"f3": pd.Series(base_signal).rolling(5, min_periods=1).mean().values,
"f4": pd.Series(base_signal).rolling(10, min_periods=1).std().fillna(0).values,
"f5": rng.normal(0, 0.5, n_samples), # noise feature
"f6": seasonal + rng.normal(0, 0.3, n_samples),
"f7": np.clip(np.gradient(base_signal), -5, 5),
})
# Target: next-step direction (binary for simplicity)
future_return = np.diff(base_signal, append=base_signal[-1])
df["target"] = (future_return > 0).astype(int)
# Drop first few rows with NaN artifacts from rolling/lag
df = df.iloc[10:].reset_index(drop=True)
print(f"Dataset: {df.shape[0]} rows × {df.shape[1]} cols")
print(f"Target balance: {df['target'].mean():.1%} positive\n")
# 2. Connect & verify
evolver = VeoxEvolver("time_series", api_url=api_url)
evolver.health_check()
# 3. Evolve
evolver.fit(
data=df,
target_column="target",
max_generations=3,
population_size=15,
num_islands=4, # 💎 PRO FEATURE: 4 parallel islands
timeout_per_eval=30,
max_poll_time=120,
)
# 4. Results
print(f"Best Score: {evolver.best_fitness_:.4f}")
print(f"Best Pipeline: {evolver.best_pipeline_}")
print(f"Evaluations: {evolver.result_.total_evals}")
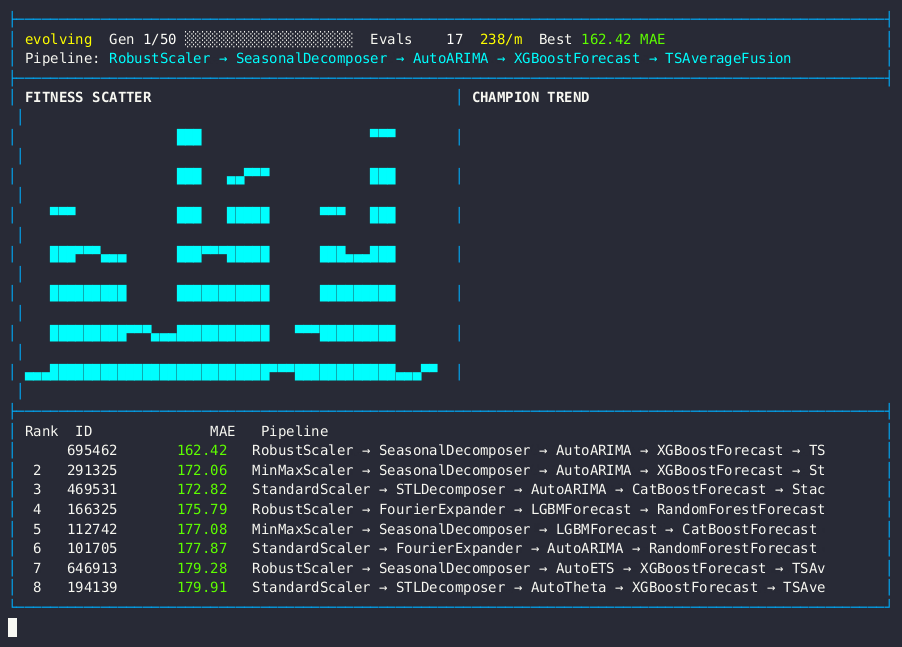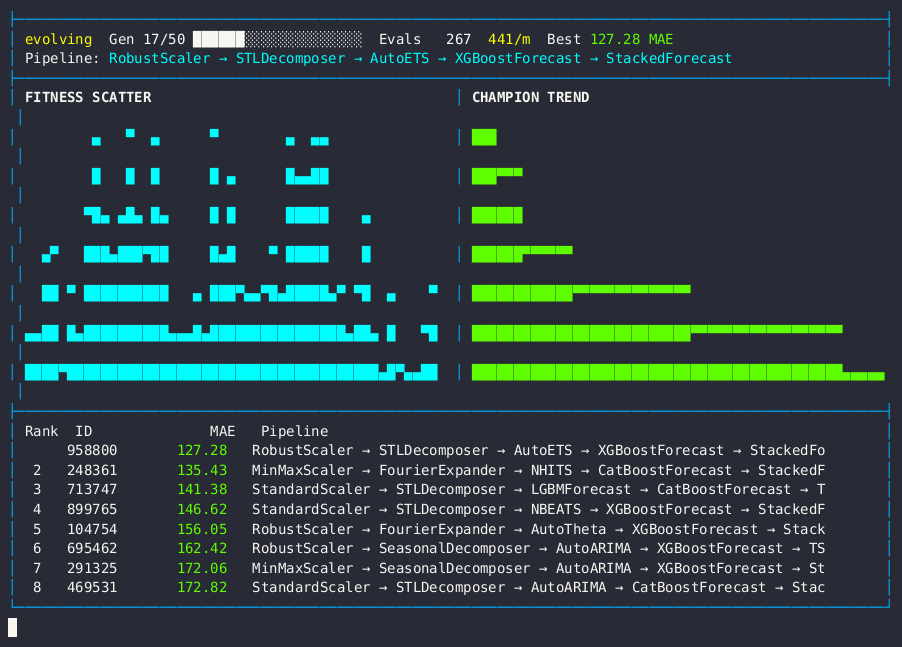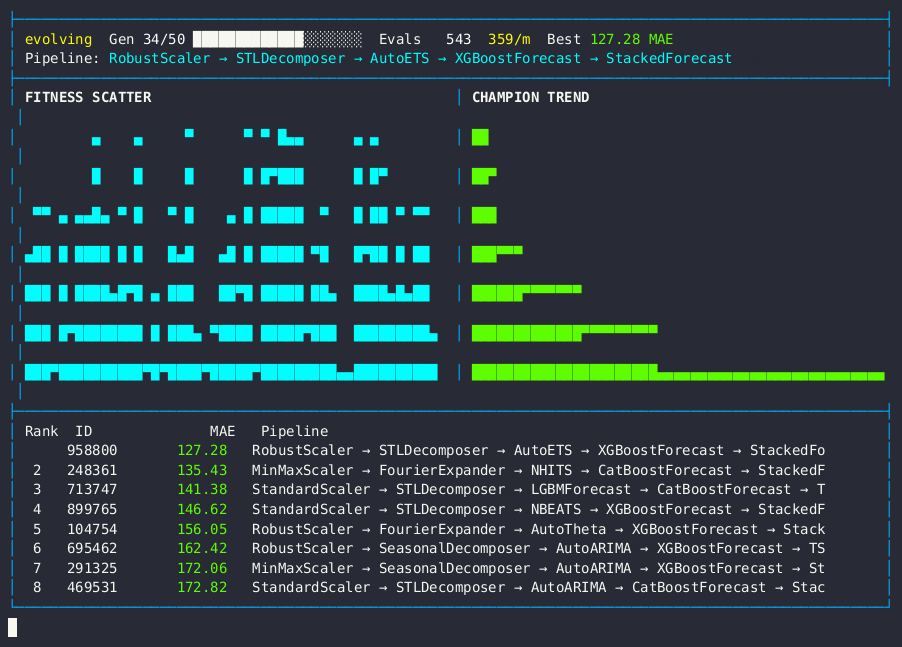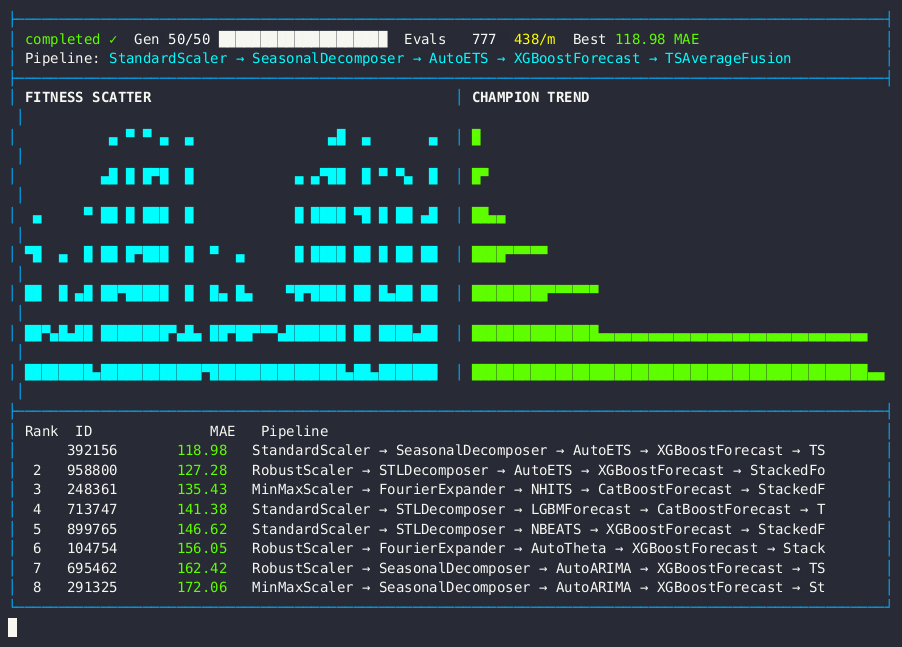
Live dashboard — MAE fitness scatter, champion trend, and forecasting pipeline leaderboard.
Fitness Configuration
| Parameter | Value |
|---|---|
| Primary Metric | MASE |
| Validation | Chronological Walk-forward splits |
| Direction | Maximize Forecast Skill |
| Exception Penalty | −2.0 |
Tip
Stationarity Matters: VEOX can automatically difference time series if unit roots are detected, but passing clean, stationary features yields faster convergence.
💎 VEOX Pro Activation
To unlock VIP Evaluators and Pro Algorithms (like PaperKit and Generative routines), you must authenticate your local node with a VEOX License Token.
from veox import VeoxEvolver
evolver = VeoxEvolver("time_series", api_url="http://127.0.0.1:8090")
# 1. Fetch your unique Hardware Fingerprint
fingerprint = evolver.get_system_fingerprint()
print(f"My VEOX Node Fingerprint: {fingerprint}")
# Example Output: My VEOX Node Fingerprint: 476ad03474b31e3c84d07df9088d93f0
# 2. Provide this fingerprint to your VEOX Admin to receive a JWT Token
jwt_token = "eyJ0b2tlbiI6ICJVRExK...EXPIRES" # Replace with your token
# 3. Activate the Enclave
if evolver.activate_license(jwt_token):
print("VIP Features Unlocked!")
# evolver.fit(...) will now utilize full Pro capabilities
Multiple Datasets
Pass multiple time series to evolve forecasters that generalize across different series:
import pandas as pd
import numpy as np
from veox import VeoxEvolver
# Time series must have columns: unique_id, ds (datetime), y (target)
def make_ts_df(name, freq="D", length=200, seed=42):
rng = np.random.default_rng(seed)
dates = pd.date_range("2020-01-01", periods=length, freq=freq)
trend = np.linspace(10, 50, length)
noise = rng.normal(0, 3, length)
return pd.DataFrame({
"unique_id": name,
"ds": dates,
"y": trend + noise,
})
df1 = make_ts_df("energy_demand", seed=42)
df2 = make_ts_df("web_traffic", seed=99)
evolver = VeoxEvolver("time_series")
evolver.fit(
data=[df1, df2],
target_column="y",
max_generations=5,
)
print(f"Best MAE (averaged): {evolver.best_fitness_:.4f}")
Tips
- Columns required:
unique_id,ds(datetime),y(target value). - Stationarity: VEOX can auto-difference, but clean features converge faster.
- Multiple datasets: Pass a list of DataFrames to test generalization.
- File paths: Use
data=["series_a.csv", "series_b.csv"]for disk-based loading.