🎯 Binary Classification
Evolve ML pipelines that maximize AUC on binary classification tasks.
Prerequisites
-
VEOX Server: Start the local VEOX server (requires Docker):
See the Quick Start for detailed server setup, health checks, and Docker Compose instructions.docker run -d \ --name veox-enclave-server \ -p 8090:8090 \ 714044927654.dkr.ecr.us-east-2.amazonaws.com/doug/single_enclave/veox-enclave-server:latest -
Python SDK: Install the
veoxpackage via PyPI:
What It Does
The binary family genetically evolves multi-stage ML pipelines:
Each stage is drawn from a library of interchangeable components. The engine evaluates candidates using K-fold cross-validation and scores them on AUC (Area Under ROC Curve).
Quick Start
from sklearn.datasets import make_classification
import pandas as pd
from veox import VeoxEvolver
# Generate a challenging binary dataset
X, y = make_classification(n_samples=500, n_features=20, n_informative=10,
n_redundant=4, n_clusters_per_class=2, random_state=42)
df = pd.DataFrame(X, columns=[f"f{i}" for i in range(20)])
df["target"] = y
# Evolve!
evolver = VeoxEvolver("binary")
evolver.fit(data=df, target_column="target", max_generations=5)
print(f"Best AUC: {evolver.best_fitness_:.4f}")
Full Example
from sklearn.datasets import make_classification
import pandas as pd
from veox import VeoxEvolver
# 1. Generate challenging dataset
X, y = make_classification(
n_samples=1000, # 1000 samples
n_features=20, # 20 features
n_informative=12, # 12 informative
n_redundant=4, # 4 redundant
n_clusters_per_class=3,
flip_y=0.05, # 5% label noise
random_state=42,
)
df = pd.DataFrame(X, columns=[f"feature_{i}" for i in range(20)])
df["target"] = y
print(f"Dataset: {df.shape[0]} rows × {df.shape[1]} cols")
print(f"Class balance: {y.mean():.1%} positive")
# 2. Connect & verify
evolver = VeoxEvolver("binary", api_url="http://127.0.0.1:8090")
evolver.health_check() # ✅ Server is healthy
# 3. Evolve
evolver.fit(
data=df, # Your DataFrame
target_column="target", # Target column name
max_generations=10, # 10 generations
population_size=50, # 50 candidates per island
timeout_per_eval=30, # 30s per candidate
max_poll_time=600, # 10 min wall-clock limit
)
# 4. Inspect
print(f"Best AUC: {evolver.best_fitness_:.4f}")
print(f"Pipeline: {evolver.best_pipeline_}")
print(f"Evaluations: {evolver.result_.total_evals}")
print(f"Throughput: {evolver.result_.evals_per_minute:.1f} evals/min")
# 5. Save
evolver.save("binary_results.json")
from sklearn.datasets import make_classification
import pandas as pd
from veox import VeoxEvolver
# 1. Generate challenging dataset
X, y = make_classification(
n_samples=1000, # 1000 samples
n_features=20, # 20 features
n_informative=12, # 12 informative
n_redundant=4, # 4 redundant
n_clusters_per_class=3,
flip_y=0.05, # 5% label noise
random_state=42,
)
df = pd.DataFrame(X, columns=[f"feature_{i}" for i in range(20)])
df["target"] = y
print(f"Dataset: {df.shape[0]} rows × {df.shape[1]} cols")
print(f"Class balance: {y.mean():.1%} positive")
# 2. Connect & verify
evolver = VeoxEvolver("binary", api_url="http://127.0.0.1:8090")
evolver.health_check() # ✅ Server is healthy
# 3. Evolve
evolver.fit(
data=df, # Your DataFrame
target_column="target", # Target column name
max_generations=10, # 10 generations
population_size=50, # 50 candidates per island
num_islands=4, # 💎 PRO FEATURE: 4 parallel islands
timeout_per_eval=30, # 30s per candidate
max_poll_time=600, # 10 min wall-clock limit
)
# 4. Inspect
print(f"Best AUC: {evolver.best_fitness_:.4f}")
print(f"Pipeline: {evolver.best_pipeline_}")
print(f"Evaluations: {evolver.result_.total_evals}")
print(f"Throughput: {evolver.result_.evals_per_minute:.1f} evals/min")
# 5. Save
evolver.save("binary_results.json")
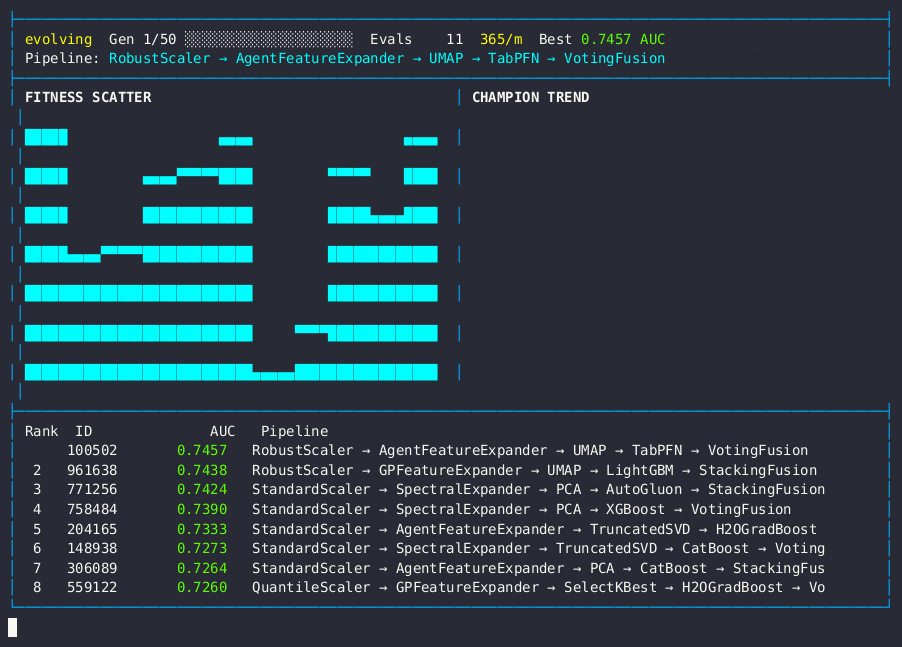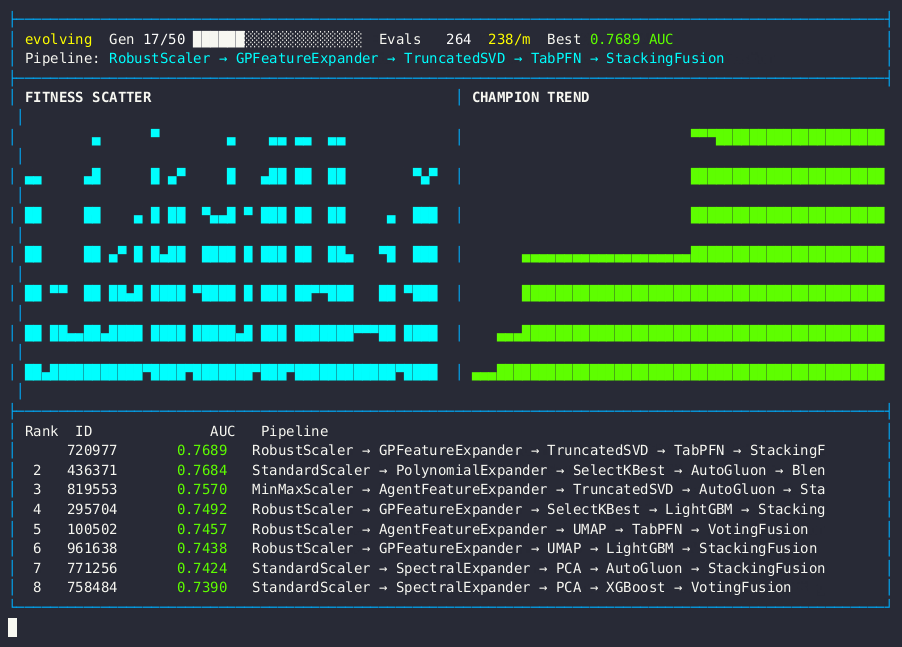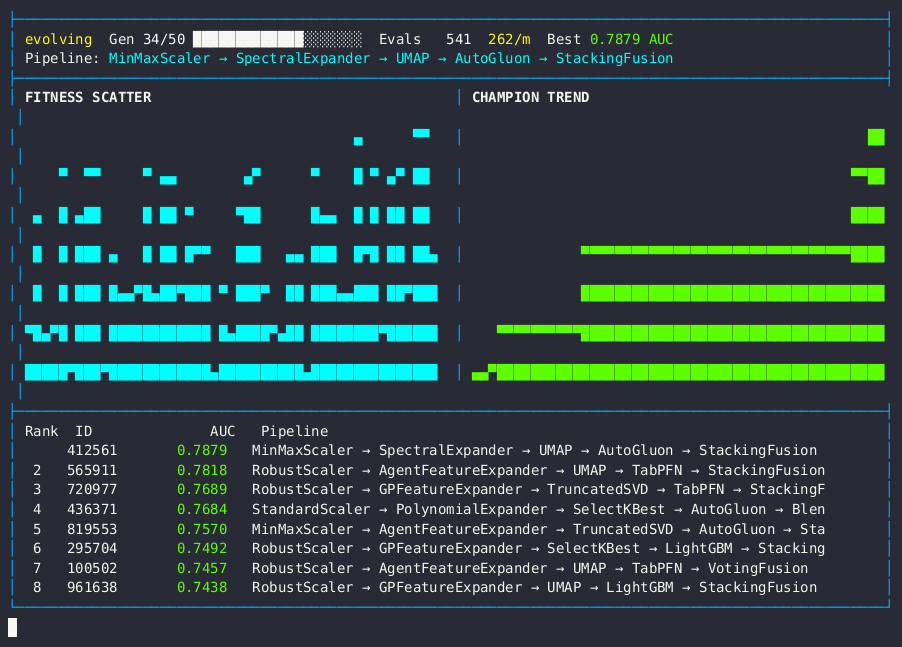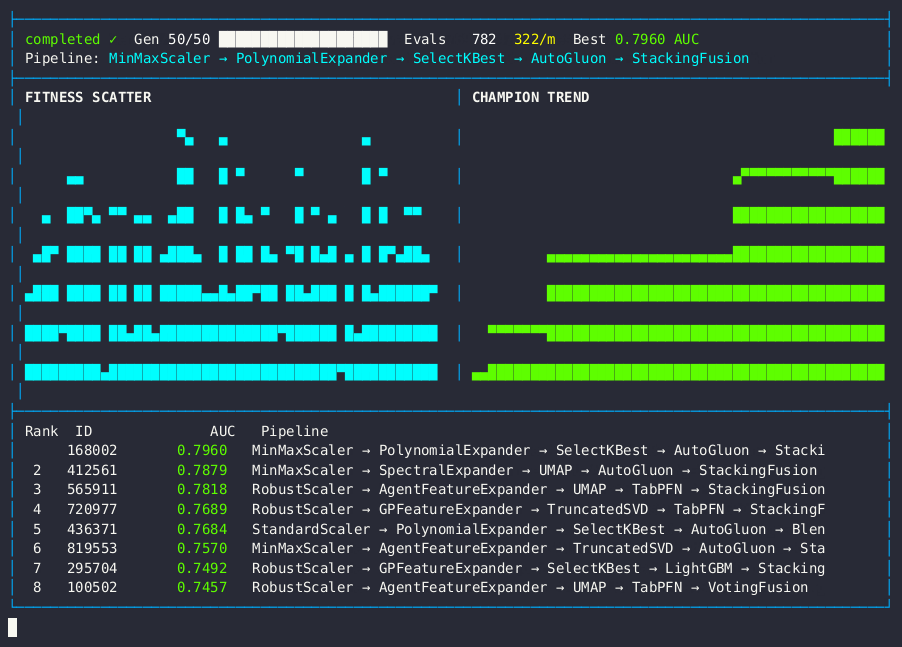
Live dashboard — AUC fitness scatter, champion trend, and pipeline leaderboard.
Pipeline Stages
| Slot | Description | Examples |
|---|---|---|
scaler |
Feature normalization | StandardScaler, MinMaxScaler, RobustScaler |
expander_1 |
Feature engineering | PolynomialExpander, GPFeatureExpander |
expander_2 |
Additional features | SpectralExpander, WaveletExpander |
reducer |
Dimensionality reduction | PCA, SelectKBest, UMAP |
model_1 |
Primary classifier | XGBoost, CatBoost, LightGBM, TabPFN |
model_2 |
Secondary classifier | Any from above pool |
model_fusion |
Ensemble combiner | StackingFusion, VotingFusion |
Fitness Configuration
| Parameter | Value |
|---|---|
| Primary Metric | AUC (Area Under ROC Curve) |
| K-Fold Splits | 3 |
| Direction | Maximize |
| Exception Penalty | −2.0 |
Open-Source Datasets to Try
# scikit-learn
from sklearn.datasets import make_classification, load_breast_cancer
from veox import VeoxEvolver
evolver = VeoxEvolver("binary")
# Breast cancer (real-world)
data = load_breast_cancer(as_frame=True)
df = data.frame
df = df.rename(columns={"target": "target"}) # Already named "target"
evolver.fit(data=df, target_column="target", max_generations=5)
# Highly imbalanced
X, y = make_classification(n_samples=2000, weights=[0.95, 0.05], random_state=42)
💎 VEOX Pro Activation
To unlock VIP Evaluators and Pro Algorithms (like PaperKit and Generative routines), you must authenticate your local node with a VEOX License Token.
from veox import VeoxEvolver
evolver = VeoxEvolver("binary", api_url="http://127.0.0.1:8090")
# 1. Fetch your unique Hardware Fingerprint
fingerprint = evolver.get_system_fingerprint()
print(f"My VEOX Node Fingerprint: {fingerprint}")
# Example Output: My VEOX Node Fingerprint: 476ad03474b31e3c84d07df9088d93f0
# 2. Provide this fingerprint to your VEOX Admin to receive a JWT Token
jwt_token = "eyJ0b2tlbiI6ICJVRExK...EXPIRES" # Replace with your token
# 3. Activate the Enclave
if evolver.activate_license(jwt_token):
print("VIP Features Unlocked!")
# evolver.fit(...) will now utilize full Pro capabilities
Multiple Datasets
Train on several datasets simultaneously to evolve more robust, generalizable pipelines. Fitness is averaged across all datasets — high-variance candidates are penalized automatically.
from sklearn.datasets import make_classification
import pandas as pd
from veox import VeoxEvolver
# Generate two independent classification datasets
def make_df(seed, noise=0.05):
X, y = make_classification(
n_samples=800, n_features=20, n_informative=12,
flip_y=noise, random_state=seed,
)
df = pd.DataFrame(X, columns=[f"f{i}" for i in range(20)])
df["target"] = y
return df
df1 = make_df(seed=42, noise=0.03) # Low noise
df2 = make_df(seed=99, noise=0.10) # High noise
evolver = VeoxEvolver("binary")
# Pass a list of DataFrames — engine evaluates on ALL of them
evolver.fit(
data=[df1, df2], # ← list of DataFrames
target_column="target",
max_generations=5,
)
print(f"Best AUC (averaged over 2 datasets): {evolver.best_fitness_:.4f}")
File paths & pathlib.Path
You can also pass CSV file paths (or pathlib.Path objects) instead of
DataFrames — this avoids loading everything into memory:
Tips
- Start small: Use
population_size=20, max_generations=3for quick tests. - GPU models: TabPFN and FMLTabPFN use GPU when available.
- Custom fitness: Inject your own metric with
custom_fitness_code=. - Callbacks: Use
on_champion=to log new discoveries to MLflow, W&B, etc. - Multiple datasets: Pass a list:
data=[df1, df2, df3]— see section above.