🔍 Outlier Detection
Evolve anomaly detection pipelines that maximize AUC on outlier tasks.
Prerequisites
-
VEOX Server: Start the local VEOX server (requires Docker):
See the Quick Start for detailed server setup, health checks, and Docker Compose instructions.docker run -d \ --name veox-enclave-server \ -p 8090:8090 \ 714044927654.dkr.ecr.us-east-2.amazonaws.com/doug/single_enclave/veox-enclave-server:latest -
Python SDK: Install the
veoxpackage via PyPI:
What It Does
The outlier family evolves multi-stage anomaly detection pipelines:
Each candidate is scored on its ability to distinguish normal samples from anomalies, measured by AUC (Area Under ROC Curve).
Quick Start
from sklearn.datasets import make_blobs
import numpy as np, pandas as pd
from veox import VeoxEvolver
# Generate an anomaly detection dataset
X_normal, _ = make_blobs(n_samples=900, centers=3, n_features=10, random_state=42)
X_anomaly = np.random.uniform(-10, 10, size=(100, 10)) # 10% anomalies
X = np.vstack([X_normal, X_anomaly])
y = np.array([0]*900 + [1]*100) # 0=normal, 1=anomaly
df = pd.DataFrame(X, columns=[f"f{i}" for i in range(10)])
df["target"] = y
evolver = VeoxEvolver("outlier")
evolver.fit(data=df, target_column="target", max_generations=3)
print(f"Best AUC: {evolver.best_fitness_:.4f}")
Full Example
from sklearn.datasets import make_blobs, make_classification
import numpy as np
import pandas as pd
from veox import VeoxEvolver
# 1. Build a challenging anomaly detection dataset
# Normal: 3 dense clusters, well-separated
# Anomaly: scattered uniformly + some near cluster boundaries
X_normal, labels = make_blobs(
n_samples=800, centers=3, n_features=15,
cluster_std=1.5, random_state=42
)
# Uniform anomalies (easy to detect)
X_uniform = np.random.uniform(
X_normal.min(axis=0) - 2,
X_normal.max(axis=0) + 2,
size=(100, 15)
)
# Boundary anomalies (harder to detect — near clusters but shifted)
X_boundary = X_normal[np.random.choice(800, 100)] + np.random.normal(0, 3, (100, 15))
X = np.vstack([X_normal, X_uniform, X_boundary])
y = np.array([0]*800 + [1]*100 + [1]*100) # 20% anomaly rate
# Shuffle
idx = np.random.permutation(len(X))
X, y = X[idx], y[idx]
df = pd.DataFrame(X, columns=[f"feature_{i}" for i in range(15)])
df["target"] = y
print(f"Dataset: {df.shape[0]} rows × {df.shape[1]} cols")
print(f"Anomaly rate: {y.mean():.1%}")
# 2. Connect
evolver = VeoxEvolver("outlier", api_url="http://127.0.0.1:8090")
evolver.health_check()
# 3. Evolve
evolver.fit(
data=df,
target_column="target",
max_generations=5,
population_size=30,
timeout_per_eval=30,
max_poll_time=600,
)
# 4. Inspect
print(f"Best AUC: {evolver.best_fitness_:.4f}")
print(f"Pipeline: {evolver.best_pipeline_}")
print(f"Evaluations: {evolver.result_.total_evals}")
# 5. Save
evolver.save("outlier_results.json")
from sklearn.datasets import make_blobs, make_classification
import numpy as np
import pandas as pd
from veox import VeoxEvolver
# 1. Build a challenging anomaly detection dataset
# Normal: 3 dense clusters, well-separated
# Anomaly: scattered uniformly + some near cluster boundaries
X_normal, labels = make_blobs(
n_samples=800, centers=3, n_features=15,
cluster_std=1.5, random_state=42
)
# Uniform anomalies (easy to detect)
X_uniform = np.random.uniform(
X_normal.min(axis=0) - 2,
X_normal.max(axis=0) + 2,
size=(100, 15)
)
# Boundary anomalies (harder to detect — near clusters but shifted)
X_boundary = X_normal[np.random.choice(800, 100)] + np.random.normal(0, 3, (100, 15))
X = np.vstack([X_normal, X_uniform, X_boundary])
y = np.array([0]*800 + [1]*100 + [1]*100) # 20% anomaly rate
# Shuffle
idx = np.random.permutation(len(X))
X, y = X[idx], y[idx]
df = pd.DataFrame(X, columns=[f"feature_{i}" for i in range(15)])
df["target"] = y
print(f"Dataset: {df.shape[0]} rows × {df.shape[1]} cols")
print(f"Anomaly rate: {y.mean():.1%}")
# 2. Connect
evolver = VeoxEvolver("outlier", api_url="http://127.0.0.1:8090")
evolver.health_check()
# 3. Evolve
evolver.fit(
data=df,
target_column="target",
max_generations=5,
population_size=30,
num_islands=4, # 💎 PRO FEATURE: 4 parallel islands
timeout_per_eval=30,
max_poll_time=600,
)
# 4. Inspect
print(f"Best AUC: {evolver.best_fitness_:.4f}")
print(f"Pipeline: {evolver.best_pipeline_}")
print(f"Evaluations: {evolver.result_.total_evals}")
# 5. Save
evolver.save("outlier_results.json")
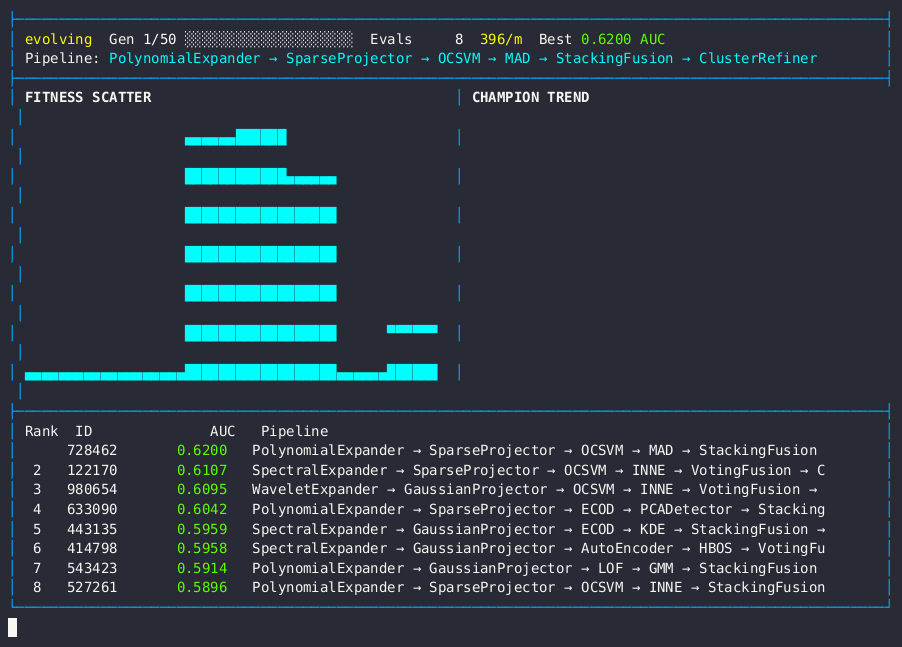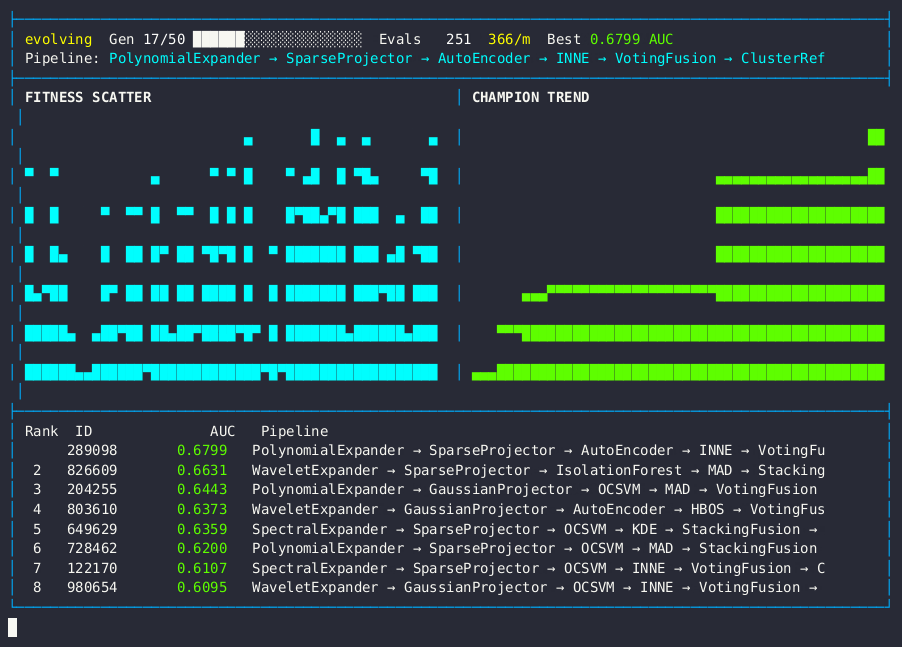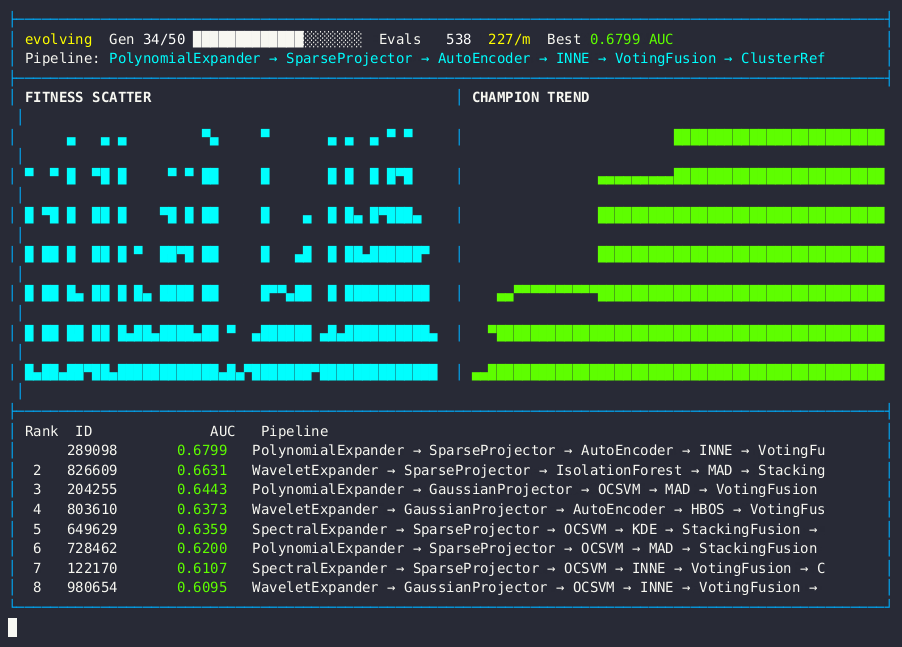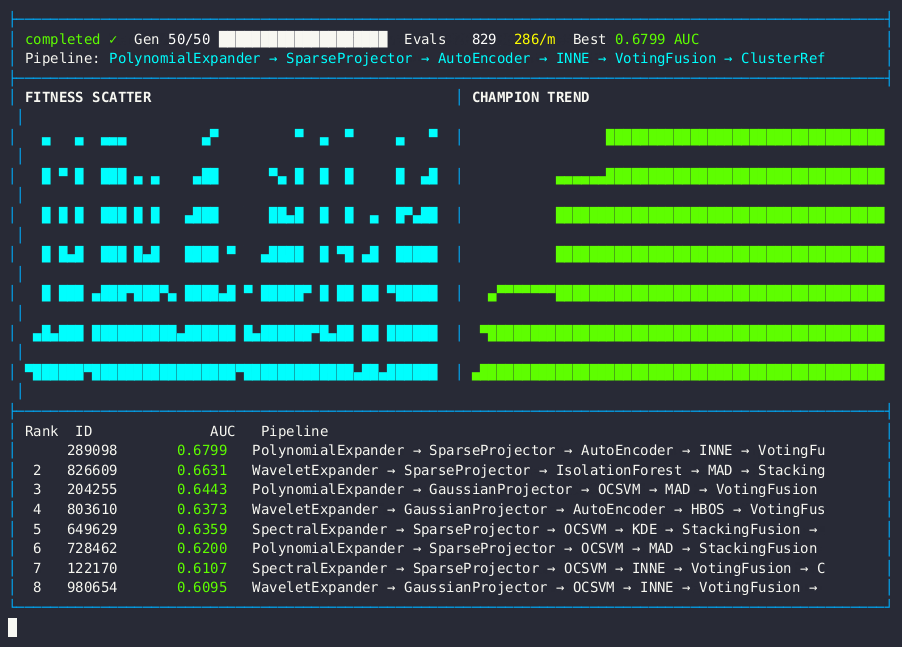
Live dashboard — AUC fitness scatter, champion trend, and anomaly detection pipeline leaderboard.
Fitness Configuration
| Parameter | Value |
|---|---|
| Primary Metric | PR-AUC (Area Under Precision-Recall Curve) |
| Target column | 0=normal, 1=anomaly |
| K-Fold Splits | 3 |
| Direction | Maximize |
| Exception Penalty | −2.0 |
Open-Source Datasets to Try
# Credit card fraud (highly imbalanced, real-world)
# pip install kaggle && kaggle datasets download mlg-ulb/creditcardfraud
import pandas as pd
df = pd.read_csv("creditcard.csv")
df = df.rename(columns={"Class": "target"})
evolver.fit(data=df, target_column="target", max_generations=5)
# Synthetic with sklearn
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=2000, n_features=20, weights=[0.95, 0.05], random_state=42)
df = pd.DataFrame(X)
df["target"] = y
# PyOD benchmark (if installed)
# pip install pyod
from pyod.utils.data import generate_data
X_train, X_test, y_train, y_test = generate_data(
n_train=1000, n_test=200, n_features=10, contamination=0.1
)
💎 VEOX Pro Activation
To unlock VIP Evaluators and Pro Algorithms (like PaperKit and Generative routines), you must authenticate your local node with a VEOX License Token.
from veox import VeoxEvolver
evolver = VeoxEvolver("outlier", api_url="http://127.0.0.1:8090")
# 1. Fetch your unique Hardware Fingerprint
fingerprint = evolver.get_system_fingerprint()
print(f"My VEOX Node Fingerprint: {fingerprint}")
# Example Output: My VEOX Node Fingerprint: 476ad03474b31e3c84d07df9088d93f0
# 2. Provide this fingerprint to your VEOX Admin to receive a JWT Token
jwt_token = "eyJ0b2tlbiI6ICJVRExK...EXPIRES" # Replace with your token
# 3. Activate the Enclave
if evolver.activate_license(jwt_token):
print("VIP Features Unlocked!")
# evolver.fit(...) will now utilize full Pro capabilities
Multiple Datasets
Evaluate anomaly detection pipelines across several datasets for better generalization:
from sklearn.datasets import make_classification
import pandas as pd
from veox import VeoxEvolver
# Dataset 1: Network intrusion (2% anomaly rate)
X1, y1 = make_classification(n_samples=1000, n_features=15, weights=[0.98, 0.02], random_state=42)
df1 = pd.DataFrame(X1, columns=[f"f{i}" for i in range(15)])
df1["target"] = y1
# Dataset 2: Fraud detection (5% anomaly rate)
X2, y2 = make_classification(n_samples=1000, n_features=15, weights=[0.95, 0.05], random_state=99)
df2 = pd.DataFrame(X2, columns=[f"f{i}" for i in range(15)])
df2["target"] = y2
evolver = VeoxEvolver("outlier")
evolver.fit(
data=[df1, df2],
target_column="target",
max_generations=5,
)
print(f"Best score (averaged over 2 datasets): {evolver.best_fitness_:.4f}")
Tips
- Label column: Use
0= normal,1= anomaly in the target column. - Imbalanced is normal: Real anomaly detection is usually 1-10% anomaly rate.
- CSV file: You can pass a file path directly:
data="network_traffic.csv". - Multiple datasets: Pass a list:
data=[df1, df2, df3]— see section above.